
Page 33 - Revista 2021 - 2022
P. 33
Revista de la Facultad de Ingeniería, Año 7, Número 1
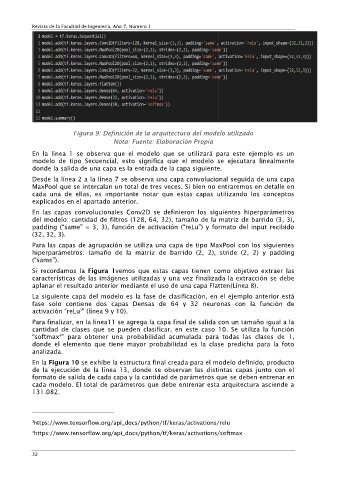
Figura 9: Definición de la arquitectura del modelo utilizado
Nota: Fuente: Elaboración Propia
En la línea 1 se observa que el modelo que se utilizará para este ejemplo es un
modelo de tipo Secuencial, esto significa que el modelo se ejecutara linealmente
donde la salida de una capa es la entrada de la capa siguiente.
Desde la línea 2 a la línea 7 se observa una capa convolucional seguida de una capa
MaxPool que se intercalan un total de tres veces. Si bien no entraremos en detalle en
cada una de ellas, es importante notar que estas capas utilizando los conceptos
explicados en el apartado anterior.
En las capas convolucionales Conv2D se definieron los siguientes hiperparámetros
del modelo: cantidad de filtros (128, 64, 32), tamaño de la matriz de barrido (3, 3),
padding (“same” = 3, 3), función de activación (“reLu”) y formato del input recibido
(32, 32, 3).
Para las capas de agrupación se utiliza una capa de tipo MaxPool con los siguientes
hiperparámetros: tamaño de la matriz de barrido (2, 2), stride (2, 2) y padding
(“same”).
Si recordamos la Figura 1vemos que estas capas tienen como objetivo extraer las
características de las imágenes utilizadas y una vez finalizada la extracción se debe
aplanar el resultado anterior mediante el uso de una capa Flatten(Línea 8).
La siguiente capa del modelo es la fase de clasificación, en el ejemplo anterior está
fase solo contiene dos capas Densas de 64 y 32 neuronas con la función de
activación “reLu ” (línea 9 y 10).
3
Para finalizar, en la línea11 se agrega la capa final de salida con un tamaño igual a la
cantidad de clases que se pueden clasificar, en este caso 10. Se utiliza la función
“softmax ” para obtener una probabilidad acumulada para todas las clases de 1,
4
donde el elemento que tiene mayor probabilidad es la clase predicha para la foto
analizada.
En la Figura 10 se exhibe la estructura final creada para el modelo definido, producto
de la ejecución de la línea 13, donde se observan las distintas capas junto con el
formato de salida de cada capa y la cantidad de parámetros que se deben entrenar en
cada modelo. El total de parámetros que debe entrenar esta arquitectura asciende a
131.082.
3 https://www.tensorflow.org/api_docs/python/tf/keras/activations/relu
4 https://www.tensorflow.org/api_docs/python/tf/keras/activations/softmax
32